因子の抽出
文章を単語に分解して、それを起点にしてさまざまな解析を実行する。これを総称してテキストマイニングというが、本章ではシートとレポートの自己評価に関する自由記述のうち、図表1に示した品詞を中心にして因子分析を行った。本来ならば毎回のシートの記述にもとづいて分析を行うべきだが、この講義が1話完結であって講義期間中一貫した因子を抽出しにくいことと、除退可能性の判別には講義を取り組んだ自己評価の記述の方が適していると判断したことによる。
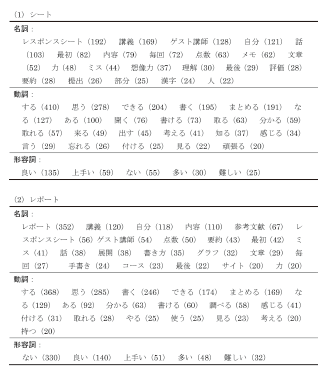
[図表1]自己評価自由記述の頻出単語(出現頻度20 回以上)
注: ①( )は出現頻度。1 つのテキストで同一単語が複数出た場合、出た数そのままカ ウントしている。
②類似した意味を持つ複数の表現は統一している。
シート自己評価の記述に現れる単語群から3つの因子を抽出した。その結果がに図表2にまとめられている。
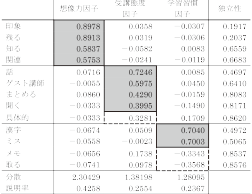
[図表2]シート自己評価自由記述の因子分析
注:因子抽出は主因子法、回転はバリマックス回転による
第1因子は、「印象」「残る」「知る」「関連」などの単語で因子負荷量が高い。前述したように、学生の作成するシートは各ゲストの講義内容をコンパクトにまとめるのと同時に、ゲストの話で〈印象に残ったこと〉と〈講義内容に関連して知りたいこと〉への記述も要求される。
他の実践において講義の感想しか書かせないミニッツペーパーなどが散見されるが、私が実践するシートでは講義内容からどれだけ想像力を膨らませることができるかも問うている。そして、それはルーブリックを通じて成績評価に反映される(図表3参照)。

[図表3]ルーブリックサンプル